







*如果看不到影片請直接點選標題連結至該網頁觀看
有如魔法電影中的情境一樣,只要用手凌空比劃兩下就可以任意開關家電或操控機器。這不是虛擬的科幻情節,本系「多媒體互動技術實驗室」利用現今的肢體追蹤與感測裝置並結合先進的圖形辨識技術就可以實現這樣的魔法世界。一般的手勢操控技術僅允許使用者一次比劃一個手勢做單一的操控動作,我們的技術卻可讓使用者一次比劃多個手勢同時進行多個操控動作。由於凌空比劃時所有的手勢都會形成一個「一筆劃」軌跡,此技術必須能很聰明地從一筆劃軌跡中精準地切割與辨識出每個連在一起的手勢,才能正確地遙控家電和機器,這就是本技術突破且創新之處。這樣的技術,可以讓使用者擺脫保管與攜帶遙控器或手持裝置的累贅負擔,也可免除不同使用者直接以手觸摸遙控裝置時的衛生考量,將來的可能應用很廣泛,除了遙控家電與機器外,還可以用在諸如門禁用途的隱形密碼、餐飲商店的無單點餐、凌空手寫輸入等等。
當您聽到一小段旋律,但不知道歌曲名稱也不知道演唱者時想要在網路上找到包含這段旋律的歌曲怎麼辦?「小段旋律哼唱搜尋系統」讓使用者哼唱一小段旋律,系統 可抽取出旋律的聲調特徵,然後與資料庫歌曲做比對,不僅可以找出包含與該小段旋律相似片段的歌曲,還可精確定位出該小片段旋律在歌曲中出現的位置,後者功 能是現有許多哼唱檢索系統中所沒有的功能,本系統之技術未來還可作為歌曲旋律抄襲偵測的應用基礎。
整合聽覺視覺多模式互動小畫家 本系統利用語音辨識技術讓使用者以語音操控電腦繪圖,並以電腦視覺技術即時偵測追蹤投影幕上的雷色光點,讓使用者利用一般簡報用的雷射比替代滑鼠,藉此實現一個更自然好用的人機界面。
使用多區域相互關係技術應用於修補影像之偽造偵測快速演算法 – 數位影像與視覺計算實驗室
過去十年間,由於數位影像的普及和強大的影像處理軟體使得數位影像偽造問題變得越來越重要,數位影像鑑識就是用來識別影像真實性,近來,許多研究者提出不同的方法能夠有效偵測出偽造區域,大部分偵測的影像以影像處理軟體所產生偽造影像為主,較少研究者注意到exemplar-based inpainting technique也能夠產生幾可亂真的偽造影像。在本論文中,我們專注在偵測inpainting偽造影像的研究。我們提出一個快速且有效的偽造偵測演算法針對inpainting偽造影像。我們的演算法分成相似度偵測和偽造區域偵測,在相似度偵測中,我們計算影像中區域之間的相似度尋找高相似度之區域,這些區域被稱為可疑區域 (Region of Suspicious),另外,依據區域之間的高相似度,我們使用corresponding vector提升辨識具有uniform background偽造影像的準確率。在偽造區域偵測中,我們使用一個多區域相互關係(Multi-Region Correlation) 技術能夠正確地識別偽造區域。此外為了改善similarity detection的效能,我們提出一個快速搜尋演算法基於權重轉換。實驗結果顯示我們的演算法能夠快速且準確找出範例式影像修補的偽造區域。

使用自動挑選區塊及色彩和諧化方法之藝術家畫風轉換研究 – 數位影像與視覺計算實驗室
畫風轉換是把一張影像轉換成某個畫家風格的研究。在前人的研究中,如果想要進行畫風轉換的話,使用者必須從畫家的作品中選擇一到數塊可以代表畫家風格的區塊。想要從很多張畫家的作品中找到適合的區塊,是相當費時而且主觀的。為了解決這個問題,我們提出了一個自動從資料庫中,選擇適合區塊的方法。首先,我們將畫家的畫作們進行平均值移動演算法的影像切割,切割出來的區域分別再使用材質重新合成的方法,就可以得到一塊塊畫家風格的區塊,所有的區塊將會儲存在畫家的資料庫中。接下來,我們使用了七種有關材質特徵的計算,讓系統能從畫家資料庫中自動的找出適合目標影像的畫家風格區塊。最後透過基於區塊樣本的材質合成技術來得到最後的結果。除此之外,我們引入了色彩和諧化的理論,讓原本產生的畫家風格影像,根據不同的和諧方案,產生不同感覺的色彩和諧結果。實驗的結果顯示我們提出的系統的確可以幫助使用者從數百張中選出適合目標影像的畫風區塊,並且產生具有畫家風格的影像。

利用單張影像3D回復技術之數位物件萃取合成系統應用於變異性光線及光影環境中之研究– 數位影像與視覺計算實驗室
萃取與合成技術(Matting and Compositing),最早原本只是用以解決電影科技中的特效合成問題,即處理在前景物件與新背景交接的邊緣區域(Boundary Regions),若是較為複雜的材質特性,如:樹木、毛髮、水、煙或一些具透光性(Light Transmittance)的材質等,因為光線的折射(Refraction),造成影像中之像素同時接收到前景與背景的光線,此混合(Mix)的比例稱為Alpha值(Alpha Value)。所以,為了降低原背景的複雜度(Complexity),往往需要花費昂貴的成本於攝影棚內搭建藍幕(Blue Screen)的背景,並將前景物件置於其中,但在前景物件的邊緣區域也可能會產生泛著原背景顏色的現象,且前景物件不能與藍幕背景顏色相同,也無法應用於一般現實生活的場景之中。此外,數位化影像的取得十分容易,如何在既能節省昂貴的硬體成本,又能兼具生活實用性下,獲得較為真實與完美的影像合成品質,也是我們一直想要達到的目標。因此,本論文提出了一個全新以3D技術為基礎的數位物件萃取與合成系統,使用了物件萃取技術(Digital Matting)來解決邊緣具有透光特性的前景物件,也使用了自動白平衡技術(Automatic White Balancing)來解決前景物件與新背景之間的光線狀態一致性問題。並且,還利用單張影像3D回復技術(Shape from Shading, SFS)來重建前景物件之3D深度資訊,並依新背景的光源方向進行重新打光(Relighting),來解決前景物件與新背景之間的光影狀態一致性問題,這將使得影像合成後的前景物件與新背景更能相互地融合,也使得結果更加地真實與完美,且較不易被肉眼所識破。

基於人體動作分析之真實影片卡通特效化 – 數位影像與視覺計算實驗室
本論文旨在建立一個視訊卡通特效化的系統,本系統分為兩大部分,分別為hierarchical video segmentation與video tooning with special effects。在系統的第一部分中,首先利用人體動作定義一個video structure,包含Entry shot, Action shot, and Exit shot respectively,其中Action shot為影片的核心,因此會再被分為Gimmickry period, Incubate period, and Shooting period。透過video structure幫助系統有效率的找出與特效互動的參數,我們稱之為特效參數。在系統的第二部分,我們利用mean shift segmentation對前景做卡通化。並且利用video structure切出的periods,分別求其所屬的特效參數,透過特效參數達到與特效的互動。此外特效的互動關係有三種,除了特效與人動作的互動之外也包含特效與環境的互動以及特效與特效的互動,系統透過卡通與特效的結合,使我們的卡通結果能有更多元的面貌呈現。本篇論文的主要貢獻包含三個部分:(1)系統分析人的動作建立一個video structure,將影片作階層式切割,分成shots與periods共兩層。(2)系統自動辨識人的動作,並將之結合特效,進而產生出動態的特效。(3)透過特效與特效參數的結合,特效擁有三種互動—與人的動作、環境以及其他特效。系統透過特效與互動的結合,使我們的結果比起傳統的真實影片卡通化更加生動有趣。

以結合粒子濾波器與平均向量演算法應用於三維人體動作參數追蹤 – 數位影像與視覺計算實驗室
人體動作追蹤在電腦視覺這塊領域已經發展有一段時間了,至近幾年內仍是一個非常熱門的研究題目,它包含了偵測、追蹤以及辨識人體的行為動作參數,應用的範圍相當廣泛,包含了醫學分析、虛擬實境、生物統計學、視訊監控以及遊戲等等。但是這方面的研究往往受限於實驗的環境以及目前的追蹤技術,使其一直無法有很大的突破,傳統的作法是在人體上裝置大量的感應器(Motion Capturing Sensor),透過感應器回傳的3D座標,可以重建出人體的動作參數,但是由於器材過於昂貴且裝置大量的感應器在身上也相當不符合現實的實用性,所以我們試著開發一套系統,以三維人體模型作動作估測的比對方式(model-based),早期大部分研究中所使用的方法是利用多台camera由各個不同的角度拍攝來重建出人體的動作,但是考量到其實用性以及方便性,因此我們僅採用單一視角所拍攝的一般影片,使用者不需要穿著特殊的服飾或是帶上大量的感應器。在本論文提出了一個漸進式粒子濾波器有效的來降低了計算量以及提高了人體動作參數追蹤的準確度。漸進式粒子濾波器為結合階層式收尋法、粒子濾波器的隨機預測技術以及平均向量演算法遞迴收尋的機制。由於一般人體動作為非線性以及非規則化,粒子濾波器透過隨機預測的技術來估測人體多變的行為。由於人體動作相當的維度非常高,透過階層式收尋法有效則可有效的分解原本需要收尋的大維度空間,本系統將人體分成三個主要的階層,再分別使用各階層分群的粒子濾波器去擷取裡面的參數,由於各階層所需收尋的範圍變小了,所以此技術成功的提升了收尋的速度以及降低了計算量,另外我們將粒子濾波器裡的各粒子內嵌入一個平均向量追蹤器,平均向量追蹤器會慢慢的移動各粒子使其往附近高機率的位置移動,在一定次數的遞迴收尋後,各粒子會收斂至各自局部最大機率的位置。如此一來透過平均向量追蹤器我們有效的提升了各粒子的準確度。但是由於平均向量追蹤器的收斂次數在某些情況下仍然很高,因此在本系統中又更近一步的提出了一個動態核心模型,我們根據各平均向量追蹤器在每次遞迴所估算出來的機率,動態的改變其核心的收尋範圍以降低遞迴收尋的次數。經由我們的實驗更加證明了此結合技術不僅僅提高了追蹤的準確度並且有效的降低了收尋的速度以及計算量。

基於藝術家資料庫之畫風轉換系統 – 數位影像與視覺計算實驗室
數位繪圖依據來源影像,合成一張新的具有範例影像之繪畫風格之影像。然而,合成的過程中總是需要使用者從範例影像中選擇最能夠代表其中的繪畫風格的區塊。本論文提出一個系統化的系統架構,能夠合成一張具有和範例影像同樣的繪畫風格之影像,但是不需要使用者進行任何額外的工作。在這份研究中,同時提出一個藝術家風格的資料庫,這個資料庫能夠讓使用者合成一張任何他所想要的著名的藝術家的繪畫風格。我們使用平均值移動演算法來進行影像切割的動作,加上材質重新合成的方法,來建構我們的藝術家資料庫。並且在範例影像和來源影像中,找出區塊間彼此相對應的關係,並且使用基於區塊樣本的材質合成技術來合成最後的輸出影像。這篇論文的主要貢獻在於一個系統化的架構,來合成影像,並且不需要經由任何使用者的幫助。藝術家資料庫是由材質重新合成過的影像切割區塊所建構而成的。基於藝術家資料庫的建構,使用者可以選取任何他所想要的藝術家風格,來進行合成的工作,並且在合成的過程中,系統會自動地挑選最適合的畫風來進行合成的動作,完全不需要使用者的介入,也能產生出一張全新的具有某種藝術家繪畫風格的輸出影像。

基於影像深度序列之多層次視訊修補研究 – 數位影像與視覺計算實驗室
影像修補技術(image inpainting)主要是運用在修復影像中缺損的區域,使結果部分能逼近原影像的內容,但是傳統的影像修補技術只適用於修復較小的缺損區域, 因此近幾年有許多針對大範圍缺損做修補的相關技術被提出,然而這些方法再修補不同的自然影像時仍有所限制。為克服以上的缺點,本論文提出了一個穩固的影像修補演算法,該演算法主要是著重於大範圍缺損區域做修補。此演算法透過影像中邊的比例(edge ratio)來定義填補順序,其中edge ratio是被用來保留影像的結構資訊。不同與以往的演算法,在復原不同的自然影像時,不需要使用者設定演算法中參數,由實驗結果觀察,不同材質的自然影像皆可有效的透過此演算法來進行復原的動作。另外本論文也提出了一個新的視訊修補(video inpainting)系統,這個系統著重於還原視訊中多個被遮蔽的動態物體;在以往的相關的研究中,大部分提出的系統只用用於還原單一動態物體,主要原因是因為他們缺乏了視訊中的深度資訊。所以我們提出了一個結合深度資訊的視訊修補方法,使本系統可以有效還原視訊中多個被遮蔽的動態物體。從實驗結果可以看出,使用者可以任意的移除視訊中任何物體,而本系統可以正確還原被遮蔽的物體。最後本系統亦透過深度資訊來將合成多個視訊中的場景及物體予以結合,使得合成視訊的內容更加豐富。

以影片內容為基準之視訊摘要系統 – 數位影像與視覺計算實驗室
以影片內容為基準之視訊摘要系統論文摘要:在這篇論文中,我們提出了一個新的影片簡介系統架構,這個系統可以針對使用者所輸入的影片來選取他們感興趣的精采片段並做為整段影片的簡介。在本系統中會先將影片作整體內容的分析以及場景變換的偵測藉以把影片分割成許多段不同的鏡頭(shot),再選取每一個鏡頭中的關鍵畫面(key-frame)作為鏡頭分類(shot clustering)的依據。在分類的時候是根據每一個關鍵畫面的場景(scene)以及動作(motion type)作為根據,如果兩兩的鏡頭擁有相似的場景以及動作,那麼它們將會被分類到同一群(cluster)裡面。使用我們所提出的分類方法之後,使用者可以得到許多由不同場景以及動作所構成的群。之後,本系統會根據每一個鏡頭的顏色變化程度(color variation)以及物體的動作大小(motion energy)選出每一個群裡面的精采畫面(highlight)來重新建構這段影片的簡介(summary),並根據精彩畫面的重要性來決定這些鏡頭在最後的簡介中可以播放的長度,這麼一來可以讓使用者所得到的影片簡介更加的簡潔。

以多視角為基礎之運動視訊編輯系統 – 數位影像與視覺計算實驗室
在DV日漸盛行之下,以video作為應用的領域也隨之增長。以往研究從擷取影像shot,發展至abstraction、summarization等剪輯技術用於表現影片中精采的片段資訊,甚至增加audio技術讓使用者能隨著音樂的節奏觀賞精采鏡頭。然而在眾多的發展中,仍以單台攝影機作為基礎,因此在拍攝影片時會因而產生表演內容與人物特寫無法同時被擷取的狀況,因此以多台攝影機作為拍攝的工具可以達到預期的目的,讓使用者能拍攝更豐富的內容與特寫。本論文研究是以多視角影片為基礎,建立自動化的視訊編輯系統,予以解決多台攝影機拍攝之影像重合的問題。多攝影機視訊合成的問題有(1)多視角影片的同步化( video synchronization ),(2)對於影片的轉換( video switching )作為主要的討論主軸。多視角影片的同步化是把影片中本身的時間對應到共同的時間軸,在結合成影片的同時不會發生重疊的問題。本系統首先利用Abrupt video shot detection切割影片中發生瞬時變化的片段,並利用於我們所設計的video synchronization技術讓系統能搜尋到同步時間點。因為在不同角度下拍攝的人,所表現出來的速度會有相似的狀況,因此在此技術中利用velocity curve作為偵測上的特徵,並利用相似度的比較達到正確的偵測判斷。轉換影片的目的是以擷取不同影片內容讓使用者能提高興趣並能觀看到當時的重點鏡頭。本系統設計三種以內容為基礎的shot,考慮使用者對於影片所關注的部份而分成camera motion shot、face shot與fragment shot,並利用我們設計的video switching計算每段shot的重要性予以判斷是否會被結合於最終的影片。本研究實驗以球類比賽為拍攝內容。對於拍攝角度上的問題、content-based shot權重的不同、室內室外環境的改變與拍攝多人影片的問題做討論,並分析影片的同步化與shot在不同狀況下的重要性。本論文提出方法以解決多影像編輯所發生的同步化與影片轉換問題,並設計利用velocity curve、content-based shot與importance shot value來完成更順暢且活潑的影片。
使用相位保護去除雜訊來提升超音波圖形輪廓偵測 – 數位影像與視覺計算實驗室
現今國民所得提高,人們越來越重視健康問題,相對的也提升了醫療品質,在醫療儀器中不乏有超音波、電腦斷層掃描(Computed Tomography,CT)、正子斷層掃描(Position Emission Tomography, PET)及核磁共振(Magnetic Resonance Imaging,MRI)等等,其中又以超音波儀器最為普遍醫療儀器,因為其價格低、無副作用且行動力強,屬於非侵入性檢查,可以作為醫療行為的初步檢查,為醫療從業人員樂於使用的儀器之ㄧ,因此本論文以超音波影像作為研究的目標。使用snake algorithm來找尋身體組織的輪廓,其結果可以協助醫生做醫療上的判斷,但由於超音波影像易受到雜訊干擾,在使用snake描繪超音波圖形中物體輪廓時,容易造成不正確的結果。本論文提出輪廓偵測的影像前處理系統,其中結合Log-Gabor filter、contrast enhancement 、histogram equalization及Canny edge等方法,來改善超音波影像品質;首先本系統設定Log-Gabor filter中的參數來濾除超音波圖形的雜訊,藉此提高影像的清晰度;其參數包括最小波長與中心頻率之頻寬,再加入contrast enhancement和histogram equalization的影像強化功能,以提升超音波影像的對比,使物體的邊緣更加明顯,接下來使用Canny edge演算法來描繪物體邊界,最後藉助於GVF-based snake將物體輪廓描繪出來。實驗結果證明本論文所提出的前處理系統可有效提高GVF-based snake在輪廓偵測上的精確度,使結果用於醫療檢驗中更具有參考的價值。
基於多重BRDFs之複雜材質反射特性重建系統分析 – 數位影像與視覺計算實驗室
描繪技術(rendering technology)在不同的領域有很多普遍而重要的應用,例如數位典藏、多媒體娛樂、 工業製品、甚至醫療科學。除了擷取3D幾何外,如何從不同視角的影像中找出物體表面最佳的特徵,進而重建出物體表面的反射特性是個相當重要的課題。我們採用基於幾何之描繪技術,並使用BRDF Model來表達材質對光源的響應影響。本論文主要的研究目的是在建構一個自動化3D物體表面重建系統,此系統能依照相機從不同視角擷取下來的平面影像,自動計算並由系統中選擇出最合適的BRDF模型來描述並呈現此3D物體,其中包含五個重要的BRDF模型,如Phong、Blinn-Phong、Cook-Torrance、Ward和Ashikhmin模型。另外,為進一步處理複雜表面特性的物體,我們提出了一個新的群集演算法來計算最佳的BRDF參數。以往的研究大部分使用單色或單一種材質特性的物體,很少研究做到多種材質,相較於之前的研究者提出的方法,此演算法以誤差向量為條件,透過參數的近似、分群、合併、和再重新分群的程序,構成了強健的分群過程,更能處理複雜表面材質的物體。分群避免掉相同材質的頂點造成雪花雜訊的情形,增加不同材質特性分群的正確性,合併減少過多不必要的群數,使群數依據材質特性達到最小值,重新分群成左滷N分錯群的頂點回歸屬於自己的群體中,讓多種材質物體的反射特性重建得以實現。另外在參數計算的過程方面,演算法將漫射和反射部分分開計算,減少反射項的誤差對漫射項的干擾,避免整體誤差小,頂點誤差大的遺憾。實驗中,我們將由例子說明此自動化選擇系統的應用及其結果的正確性;此外,此演算法亦將應用於數個不同漫射和反射特性的材質物體上,經過參數的近似、分群、合併和重新分群的過程,重建出不同材質的反射特性,由結果的誤差量測及視覺上的呈現來驗證此演算法在處理複雜材質物體的能力。

利用主動式外觀模型(AAM) 抽取表情特徵,再以其特徵重新合成成虛擬的角色。
以視覺為基礎之指尖手寫辨識介面的設計及實作 – 多媒體互動技術實驗室
我們設計了一套低成本、高便利性和可直覺化操作的人機介面系統。利用攝影機偵測手指尖當作筆來輸入手寫文字,將得到的軌跡抽取特徵並用隱馬可夫模型比對來得到辨識結果
主動式外觀模型應用於臉部追蹤與表情合成 – 多媒體互動技術實驗室
本系統的主要核心技術是主動式外觀模型(Active Appearance Models,AAN)。藉由AAM追蹤到的人臉表情,可得到對應的臉部特徵和紋理參數。
藉由這些參數我們建立出適當的型變轉換關係,並合成出不同使用者的表情。
以動態時軸扭曲進行連續手寫軌跡分段及辨識 – 多媒體互動技術實驗室
在連續軌跡書寫的分段偵測與辨識上,首先,我們採用多邊形逼近法進行取樣,並且依照書寫順序排序後將取樣點化為特徵序列。 再以動態時軸扭曲為主的關鍵軌跡萃取法萃取出所有可能的單一數字候選軌跡。 為了減少尋成本,我們對候選軌跡繼續使用動態時軸扭曲和樣版長度的比較,將可信度較低的軌跡濾除,最後為所有候選段建立一連通圖,使用最短路搜尋法找出最可能的數字組合。
語音關鍵字萃取技術於火車時刻查詢應用 – 多媒體互動技術實驗室
在對語音辨識的方面,我們利用HMM來訓練關鍵字,並配合維特比(Modified Viterbi Search for Continuous Speech Recognition) 演算法得到句子中由那些關鍵字組成,並利用分割出來的關鍵字做語法分析。
為了追蹤駕駛者的眼睛位置,我們的系統首先從灰階影像中利用圓形頻率濾波器(circle-frequency filter) 找出between-eyes(雙眼中心連線的中點) ,然後利用中間中間穿越函數(mean crossing function) 及中央權重函數 (central weighting function) 找到兩邊的眼睛。
接著利用蘇珊濾波器(SUSAN filter) 切割出眼睛的部分,再以多層感知類神經網路(multi-layer perceptron neural network 簡稱MLP) 分析駕駛員打瞌睡與否。
在手勢偵測上,本研究不使用一般常用之膚色偵測( Skin Color Detection )技術,改以結合畫面的邊緣資訊與畫面差異法( Frame Differencing ),來減低光線和背景變化的影響。並設計有效的抗旋轉特徵來做不同手勢的初始偵測。
在手勢追蹤上,依所偵測到的指尖位置,自動產生新的追蹤模板來追蹤。對於Lucas-Kanade追蹤演算法易受複雜背景干擾的問題,本研究利用移動邊偵測( Moving Edge Detection )和距離轉換( Distance Transform )來減低複雜背景干擾。然後利用Lucas-Kanade追蹤演算法作精細的運動參數估測。當追蹤誤差無法容忍時或手勢更換時,自動再次執行指尖偵測且自動更新追蹤模板。藉著不斷的更新追蹤模板,達到比單一模板更強健的追蹤和辨識。
基於樣本塊之影像修補演算法下,對信賴度與結構度重新定義,確保找出維持結構的影像修補順序,並透過自定義的動態規則,達到更佳的修補結果。
此外,利用色調分離的方法,縮小資源區塊的搜尋範圍,使影像修補過程能改善耗時的缺點。
利用紅綠燈的色彩資訊、邊緣資訊以及區塊對稱性,逐步對交通號誌進行偵測與辨識,且使用WiRobot機器人與自製自動化紅綠燈偵測與辨識系統模擬道路現場,以逼近真實行車環境。
利用區域分割之線性子空間表示法進行物件追蹤 – 多媒體互動技術實驗室
在物件外觀模型(Appearance Model)上,透過線性子空間的轉換與即時更新,可利用低維度來降低追蹤計算量,也可即時反應物件外觀的動態變化。
此外,區域分割可使追蹤過程中隨時判斷區域遮蔽,並使用未被遮蔽的區域進行追蹤,使得此追蹤法更為可靠。
主動式外觀模型應用於嘴唇輪廓抽取與讀唇術 – 多媒體互動技術實驗室
利用主動式外觀模型(AAMs)追蹤嘴唇輪廓上的控制點,以漸進擬合(fitting)的方式更新嘴唇的網格形狀以及紋理,再以K Nearest Neighbor(KNN)辨識法找出在資料庫中最相似的嘴形作為辨識結果。
藉由連續的嘴形辨識結果來達到對使用者唇語命令的辨識,亦即一般所謂之「讀唇術」(lip reading)。
2014東海岸馬拉松「跑東馬;做公益」於3月15日順利落幕了,值得一提,此賽事所使用的資訊系統,全權由國立東華大學資訊工程學系學生所設計開發。設計學生表示,從大眾使用者角度出發,未來要讓這套系統增加更多強大且貼切之功能,並使介面更加友善,朝著國際級的運動資訊系統邁進。
此次的資訊系統為「Sport Timing System 運動計時資訊系統」(以下簡稱STS),從2009年開始規劃建置,由理工學院院長林信鋒、資訊工程學系主任吳秀陽與戴文凱教授負責主導,東華資工GAMELab的研究生們共同討論、設計以及開發,整合當時最新科技RFID感應晶片,歷經一年後完成了一套完整的運動計時資訊系統。 此系統曾支援過許多路跑與自行車賽事,而報名系統也有多場路跑、自行車及鐵人賽使用過,例如:2009「堅持轉動」縱谷單車嘉年華、2009花東縱谷國際馬拉松、新北市100年單車逍遙遊系列等,之後因設計團隊的多數成員畢業而停滯。

當人們拿到了駕駛執照後,往往開車上路總是忽略最基本的交通規則,而導致車禍發生。為了降低這類的事件發生,我們開發了一套汽車模擬駕駛系統,利用電腦模擬的方式,讓汽車駕駛人在開車上路前,先透過操作這套模擬系統,了解應遵守哪些交通規則,一旦駕駛人違規了,此套系統就會鳴笛警告,並顯示駕駛人是觸發了何種違規事項。在模擬結束後,系統會依照該駕駛人之駕駛行為給予評分,並列出此次模擬中所有的違規事項,而每項違規事項我們也依據交通處罰條例,應罰款多少金額,讓駕駛人有所警惕,達到宣傳交通安全之重要性。為了讓整個模擬過程更加真實,我們結合了遊戲賽車椅,使駕駛人更能感受到真實性。
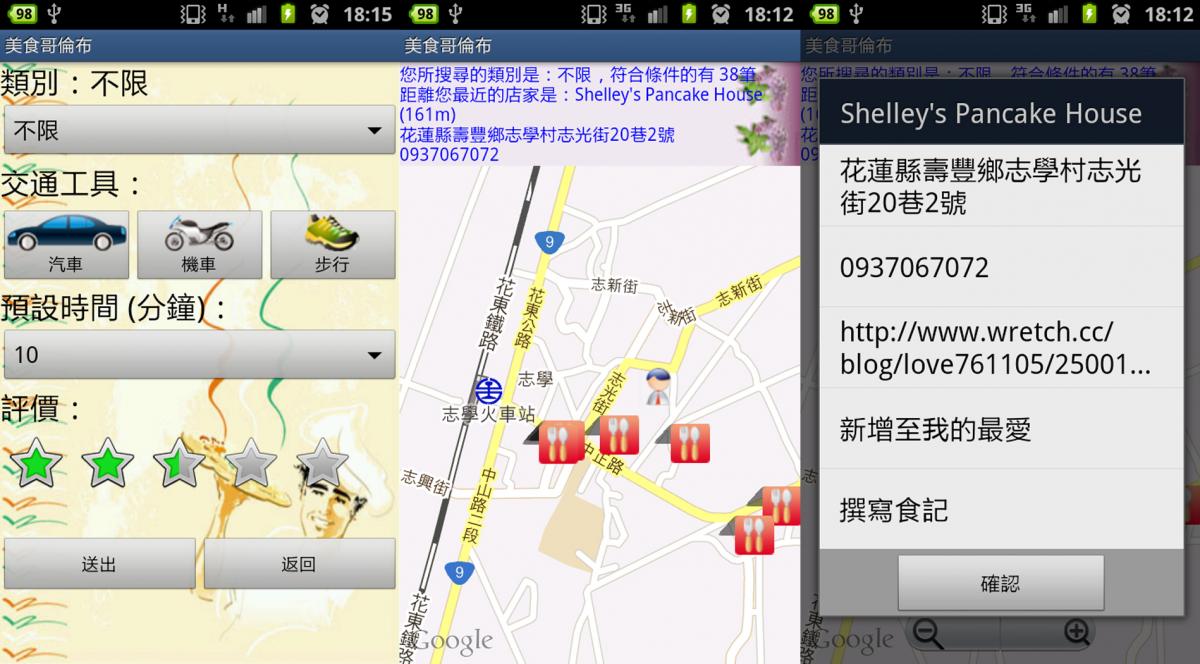
東台灣美食哥倫布 – 無線網路服務工程實驗室
「東台灣美食哥倫布」係由本系無線網路服務工程實驗室研究生周靖偉主力開發。這套東台灣美食哥倫布是以Android平台開發的一個應用程式App,主要的開發精神是希望以最便利、最豐富且多樣化的服務協助使用者。東台灣美食哥倫布在搜尋服務上提供了更人性化的搜尋條件及多樣化的搜尋服務,協助使用者快速的搜尋到符合需求的美食店家,也會依照當下區域的氣溫給予飲食方面的建議;針對一些具有特色或高人氣的地方美食列入特別推薦名單,並附上具有故事性的文字介紹,讓使用者了解店家發展的特色及精神;東台灣美食哥倫布也提供豐富的店家資訊如食記及評價等,讓使用者能對於店家提供的餐點菜色一目瞭然;此外,東台灣美食哥倫布也與社群網路做結合,讓使用者可即時分享用餐心得,並且透過打卡可享受合作店家的優惠。
本專案創造出專屬於東華人之線上網路遊戲。 結合現在推行之八大核心能力系統與學習履歷系統, 將各學生之學業能力展示於此網路遊戲中, 並讓每位學生都有自己的小屋,可以分享其成就。 學習履歷任務需要學生真正去參與該活動, 才能回東華Online上獲取獎勵。 東華島是依照東華校園打造,學生們亦可透過此網路遊戲認識東華的校園環境。